今天,拥有目前被公认为最强编程模型的宣布,旗下两款模型Opus 4.6正式升级到1M上下文窗口,两款模型Opus 4.6正式升级至1M上下文窗口,并且加量不加价,然而这价格高昂仍让不少开发者大喊“肉疼”,1M上下文时代来临,你的钱包准备好没?
百万上下文全面开放
此次升级,最为核心的变化,体现在上下文窗口的全面开放之上。自今日起,Opus 4.6 与 4.6 将默认支持高达 1M 的上下文长度,这表明模型能够一次性处理等同于三本《三体》三部曲规模大小的书籍。在此之前,若开发者想要使用超过 200K 上下文的请求,就得在代码里面加入特定的 beta 标头去进行申请。如今,这一繁杂步骤已然成为过去,所有请求都会自动予以处理,开发者无需改动任何代码就能享受到百万级别的上下文处理能力。
在实际运用当中,这一提高对于处置超长文档、大型代码库或者开展深度学术研究有着里程碑的重要意义。比如说,一个有着数十万行代码的遗留项目,如今能够完整无误地输入给模型去进行整体剖析以及重构建议,而不再需要开发者亲自手动切片与拼接。这样一种毫无缝隙间断的体验升级,将会极大程度地提升开发效率以及AI应用的深度。
媒体能力同步飞跃六倍
别说是上下文能力有着那种可称为震撼级别的增强了,就连模型的媒体处理能力也有了明显的强有力升级。依据官方所给出的信息能够知道,在这次进行升级之后,媒体能力所受到的限制已经变宽松到原来的六倍那么多了。详细讲一讲的话,就是如今每一条API请求能够做到支持去处理多达600张的图片或者600页的PDF文档。对于那些有着需要批量处理图像或者去分析大量PDF报告需求的用户而言,这绝对是如同天降甘霖般十分利于他们的事情了。
往昔之时,处理一本带有数百页的PDF书籍,或许要求多次去调用API,这般做不但耗费时间,而且还增加了代码所具有的复杂性。当下,一次进行请求,便能够完成整本书籍的图像识别或者文本分析,不管是开展数据挖掘,还是做内容摘要,都变得前所未有的便利。这一回的改进,让Opus 4.6以及4.6在多模态应用领域的实用性大幅度增强。
加量不加价的昂贵依旧
虽然此次性能有了极大幅度的提升,官方也清晰表明这一回乃是“加量却不增加价格”,上下文窗口即便扩大到了原来的五倍,可价格体系却维持不变,每个输入输出长度都存在完整的费率限制,然而这个价格自身一直以来依旧是当下市场里最为昂贵的当中的一个,Opus 4.6的百万Token输入价格为5美元,输出价格多达25美元,而4.6的输入输出价格则分别是3美元和15美元。
许多个人开发者以及中小团队,在使用这样的定价策略时,不得不精打细算。哪怕是写代码这种对模型要求特别高的场景,好多程序员也不敢全程运用这两个“贵族”模型。大家普遍采用的策略是,用它们去处理最核心、最复杂的逻辑部分,而把一些常规的代码生成或者调试任务,搭配给其他价格更为便宜的模型来完成。
超长上下文下能力保持稳定
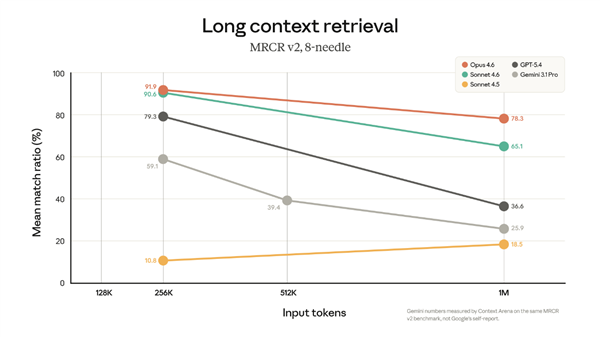
好多人存有担忧,当上下文窗口进行扩展以后,模型的理解以及推理能力就会跟着降低,然而官方公布出来的测试数据表明,Opus 4.6在提升至1M上下文时,能力基本上没有受到什么影响,尤其是在具有权威性的MRCR v2长文本检索测验里,Opus 4.6获得了78.3%的高分,这样的成绩在处于相同上下文长度的前沿模型当中位列榜首。
这表明开发者不但拥有了处理超长文本的能力,并且这种能力的拓展并未以牺牲模型的核心性能作为代价,在处理那些需要深度推理以及精准定位的百万级长文时,Opus 4.6依旧能够维持极高的准确率,这对于诸如法律文书审查、学术论文撰写等严肃应用场景来讲,是极为关键的保障。
测试模型先行惊喜不再
实则,此次的全面升级并非全然毫无迹象显示。早在今年2月时,便已然发布了测试版本,同样对1M上下文窗口予以升级。当时的实际呈现确实颇为出色,给参与内测的开发者留下了极为深刻的印象。然而,伴随美国主流的闭源大模型,像谷歌的Gemini 1.5 Pro等也普遍支持了百万级别的上下文,这项技术如今已算不上是新鲜别致的惊喜了。
整个行业针对AI能力的期待的数值正在持续被往上提升,当每一个个体都具备使用1M上下文的条件时,市场目光的聚集点再次回归到模型自身的理解能力、推理能力以及创造能力之上,对于相关方面来讲,怎样在维持上下文优势的情形下,更进一步在核心能力这个方面和其他模型之间拉开距离,这将会是未来所要面对的更为严峻的挑战。
开源追赶闭源任重道远
于社区里头,有关下一代V4 的传闻始终持续不断。当中,最大的升级亮点被广泛视作是编程能力的极大跃升,甚至有消息透露称其能力能够达到乃至超越现 当前公认最厉害的编程模型。然而这个目标对于开源模型来讲,无疑是一项极大的挑战。毕竟,闭源模型背后存在着海量资金的投入以及全球无数开发者使用过后反馈的数据优化。
想要在编程这个复杂无比的领域实现超越,除非出现全新的技术突破,不然很难在短时间内达成那样的目标。哪怕全球的开发者生态以及使用数据反馈犹如一座规模巨大的护城河,它保护着类似这样的顶级闭源模型。开源社区尽管处于蓬勃发展的态势,然而要越过这道差距极大的鸿沟,依旧需要耗费时间以及进行更多创新性的技术积累。
面临这般一波上下文达1M的升级热潮以及仍旧高昂不低的价格,于你在现实的开发过程当中究竟会挑选“咬着牙全部采用”这样的做法,抑或是坚守“混合搭配来节省钱财”的策略呢?欢迎于评论区域之内分享你所拥有的看法,点赞以及转发好促使更多的同行伙伴一同展开讨论!
